Navigating the Maze of GDPR Compliance: A Codebase Transformation
How we levaraged the repository pattern to achieve GDPR compliance

Introduction
Gone are the days when data privacy was an afterthought, something we could casually ignore with without much consequence. Today, we find ourselves in an era where GDPR compliance for our customer’s LLM data isn’t just a nice-to-have; it’s a must-have.
We faced a significant challenge: for certain customers, it was imperative to store and manage all information strictly within the European Union to comply with stringent privacy regulations. Due to challenges with our current provider and client demands, as detailed in this blog post, we had to not only offer a new data store location but also offer it using a different database provider. The idea of moving our entire database infrastructure to Europe and to a new provider was overwhelming, to say the least. It promised a surge in operational costs and the threat of reduced data access speeds. Thus, we set out on a mission to overhaul our code architecture, aiming to achieve compliance without the drastic measure of relocating.
The Repository Pattern
Our journey to compliance led us to refactor our code to ensure that every function within our systems could interact with different databases without being tied to a specific implementation (like MySQL or MongoDB). Instead, these functions would rely on an abstract database. Let’s illustrate this with a hypothetical scenario:
Imagine we’re defining a Person in our code, and this person needs to drink water. Our system must allow the user to drink from three different water sources: a bottle of water, a glass of water, and a water reservoir. The abstract water repository serves as a “contract” ensuring that every water source implementation provides what the user needs to quench their thirst.
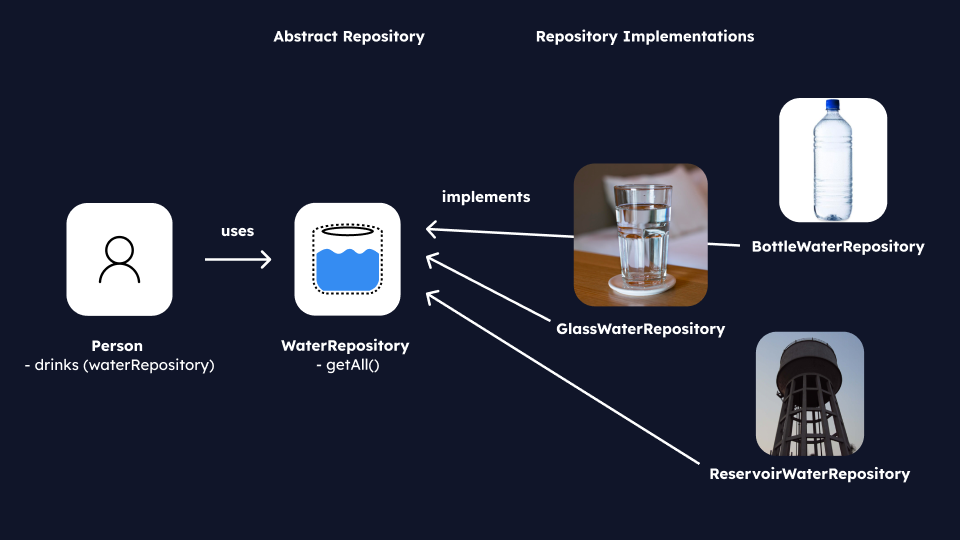
Ultimately, the “drink” function utilizes a water repository, but it’s crafted in such a way that it doesn’t depend on a specific water source implementation. Instead, it relies solely on the abstract water repository. This flexibility allows us to seamlessly integrate various water sources without the user being aware of the specific source they’re using.
This approach embodies the Dependency Inversion Principle, a concept introduced by Robert C. Martin in 1994. It’s fascinating to see how principles established before the internet took over our lives remain as relevant as ever, proving that not everything from the pre-digital era is as outdated as a floppy disk 💾.
Implementation in the Mendable Code Base
Our codebase served as an ideal testing ground for the Repository Pattern, primarily because the project was designed with a focus on delivering value and addressing customer pain points. Navigating through this type of code—evolved from an MVP yet not bogged down by years of accumulated “coding styles” from numerous developers—presented its unique set of challenges.
The biggest obstacle we encountered was breaking the strong dependency on a specific database throughout all our functions. This required weeks of diligent effort from our teams. Despite the hurdles, we remained committed to pushing forward, fixing bugs, and ultimately reaching our goal.
Conclusion
Adopting the Repository Pattern has been a game-changer. It’s not just about achieving GDPR compliance; it has transformed and opened many doors in our approach to sales and development.
Have you encountered such fundamental changes in your company? Are you able to alter the way you manage data and compliance in your projects?